DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning¶
http://arxiv.org/abs/2501.12948
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities. Through RL, DeepSeek-R1-Zero naturally emerges with numerous powerful and intriguing reasoning behaviors. However, it encounters challenges such as poor readability, and language mixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates multi-stage training and cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-o1-1217 on reasoning tasks. To support the research community, we open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama.
概述 (Content) ¶
结合 Understanding Reasoning LLMs 进行阅读,下面是来自这篇文章中的关于 DeepSeek-R1 报告中的训练流程图:
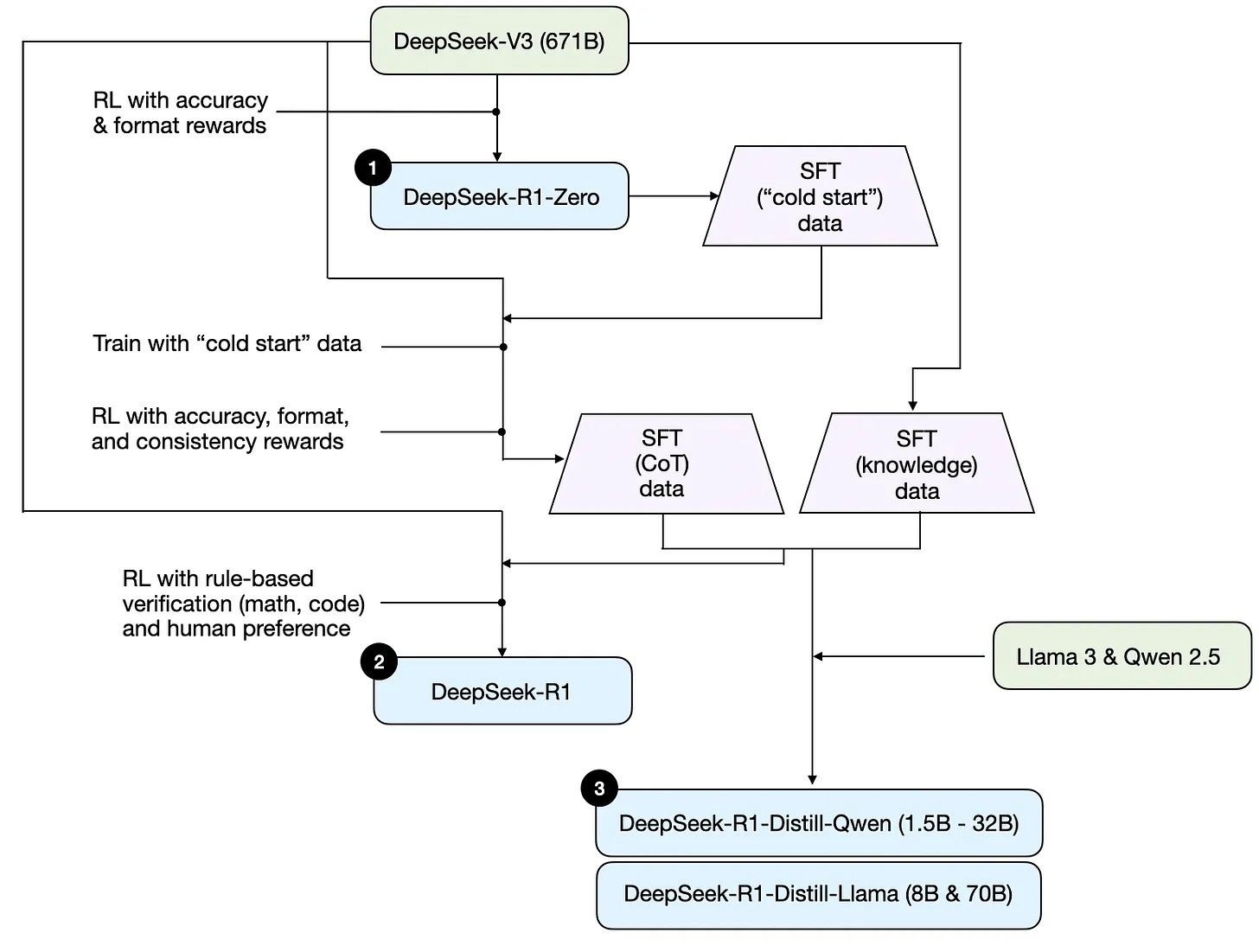
Development process of DeepSeeks three different reasoning models that are discussed in the DeepSeek R1 technical report.
方法 (How) ¶
Extra
进行了尝试,但是效益一般: - inference-time scaling - 提高 CoT 的推理时间,会显著提高推理成本; - process-based reward models - classic RL - Monte Carlo Tree Search and Beam Search
在论文中,DeepSeek 共发布了三类 R1 模型。
DeepSeek-R1-Zero (PRL)¶
以 DeepSeek-v3 为基础模型,使用纯强化学习(抛弃了过去强化学习前的 SFT 阶段
- 奖励模型:
- Accuracy reward:评估模型解决问题的能力
- format reward: 评估模型遵循格式回复的能力
DeepSeek-R1 (RL \w Cold Start)¶
DeepSeek-R1-Zero 本身未使用监督微调数据进行训练,但是 DS 团队利用其生产 SFT data,被其称为 cold start。
利用 cold start 数据对 DeepSeek-v3 进行传统的强化学习,这次还加上了 consistency rewards 以提高模型“避免语言混合”的能力。
之后再次生成 SFT 数据,重新对 DeepSeek-v3 进行了 RL 获得 DeepSeek-R1 ,并进行了对齐。
"distillation"¶
不同于传统的 “一个较小的学生模型在较大的教师模型的 logits 和目标数据集上训练”,这里的蒸馏更多指的是将更大的 LLM 所生成的 SFT 数据(即上一技术过程中产生的数据)用于对较小的 LLM 进行微调。
通过对 Qwen(1.5B-32B) 和 Llama(8B&70B) 进行微调,比较评测下发现,蒸馏模型虽然仍然远弱于 DeepSeek-R1,但在一定程度上超过了 DeepSeek-R1-Zero 以及 o1-mini 模型。
主要贡献 ¶
-
贡献
- “aha” 时刻展示了模型的 “思考能力”;
- 提出 pure reinforcement learning 和 cold start,提高了模型的推理能力;
- DeepSeek-R1 的推理能力接近于 chatgpt-o1,成本更低;
- 成功创建了多个更小、成本更低的具有较高推理能力的模型;
- 发现在 DeepSeek-R1 的情况下,zero-shot 比 fewer-shot 的效果更好;
- 开源了 DeepSeek-R1 相关所有模型。
-
局限性
- 虽然 DeepSeek-R1 在推理能力上相比 DeepSeek-v3 有了长足提升,但是在其他领域(如 function calling, multi-turn, complex role-playing)上的能力却发生了下降;
- DeepSeek-R1 基于中英文训练,在其他语言上表现较差甚至出现语言混淆;
- DeepSeek-R1 对于提示词非常敏感。
进一步工作 ¶
- 对其中的术语进行了解学习;虽然看明白了大致过程,但是对于每种缩写代表的含义,其方法针对的问题 / 带来的效果了解不够:
- RLHF: RLHF 的核心是训练一个基于人类反馈的单独的 AI 奖励模型,然后使用该模型作为奖励函数,通过 RL 优化策略,达到“对齐”的目的;
- Pre-training and Post-training:发生在预训练 (Pre-training) 之后,包括多种操作:SFT、RLHF 等;在 New LLM Pre-training and Post-training Paradigms 一文中的总结可以看出,pre-training 和 post-training 是可以灵活组合的,实际效果因模型和其他因素而异。
- 思考如何评估 DeepSeek-R1 对提示词的敏感程度,制定相应的护栏指定方案 / 手段;